Exploratory Data Analysis
2. Overall Trend in Sector Indices
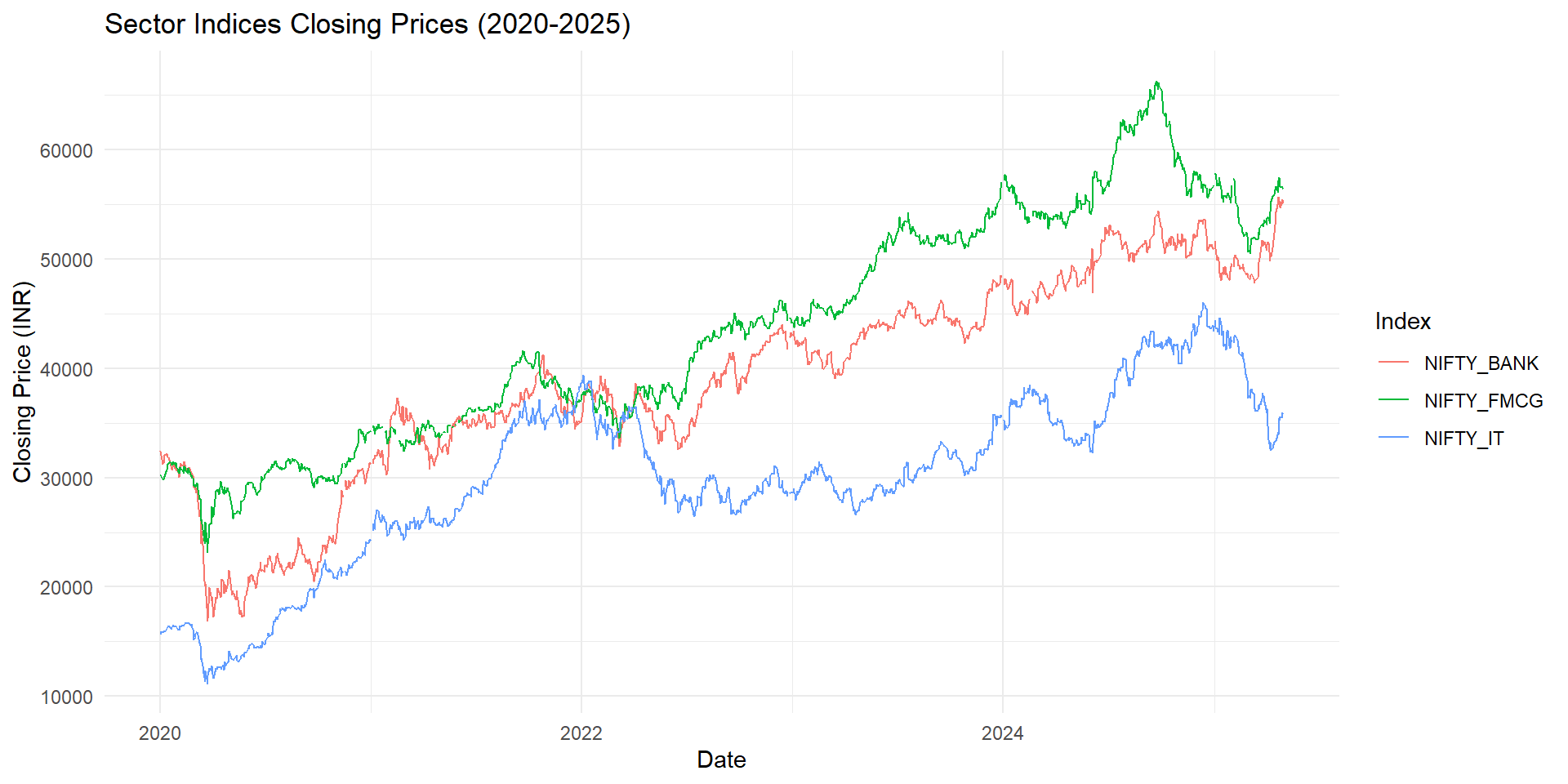
Interpretation: All sectors show upward trends with some volatility, especially Banking.
4. Distribution of Daily Returns
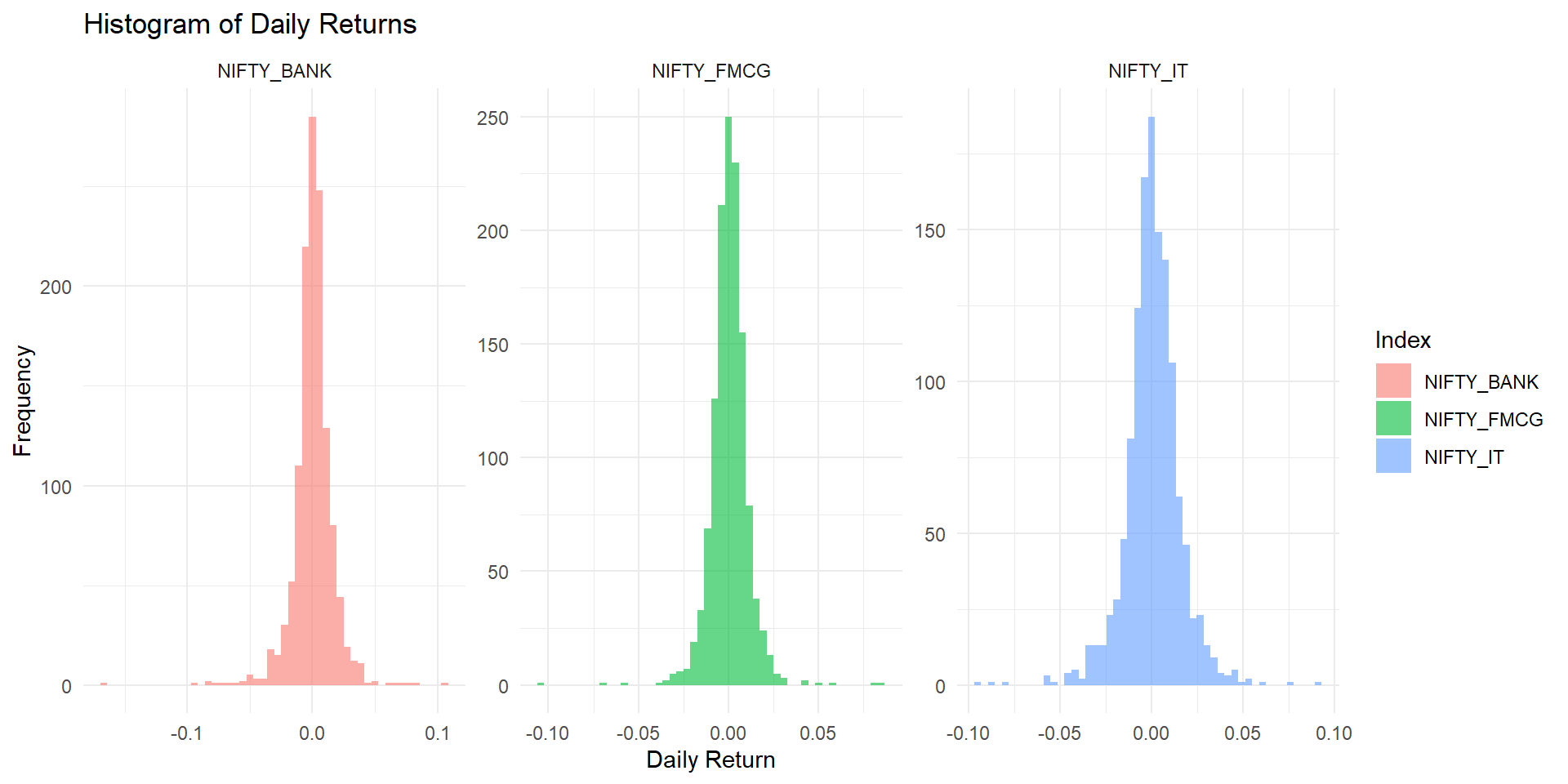
5. Normality Check with QQ Plot
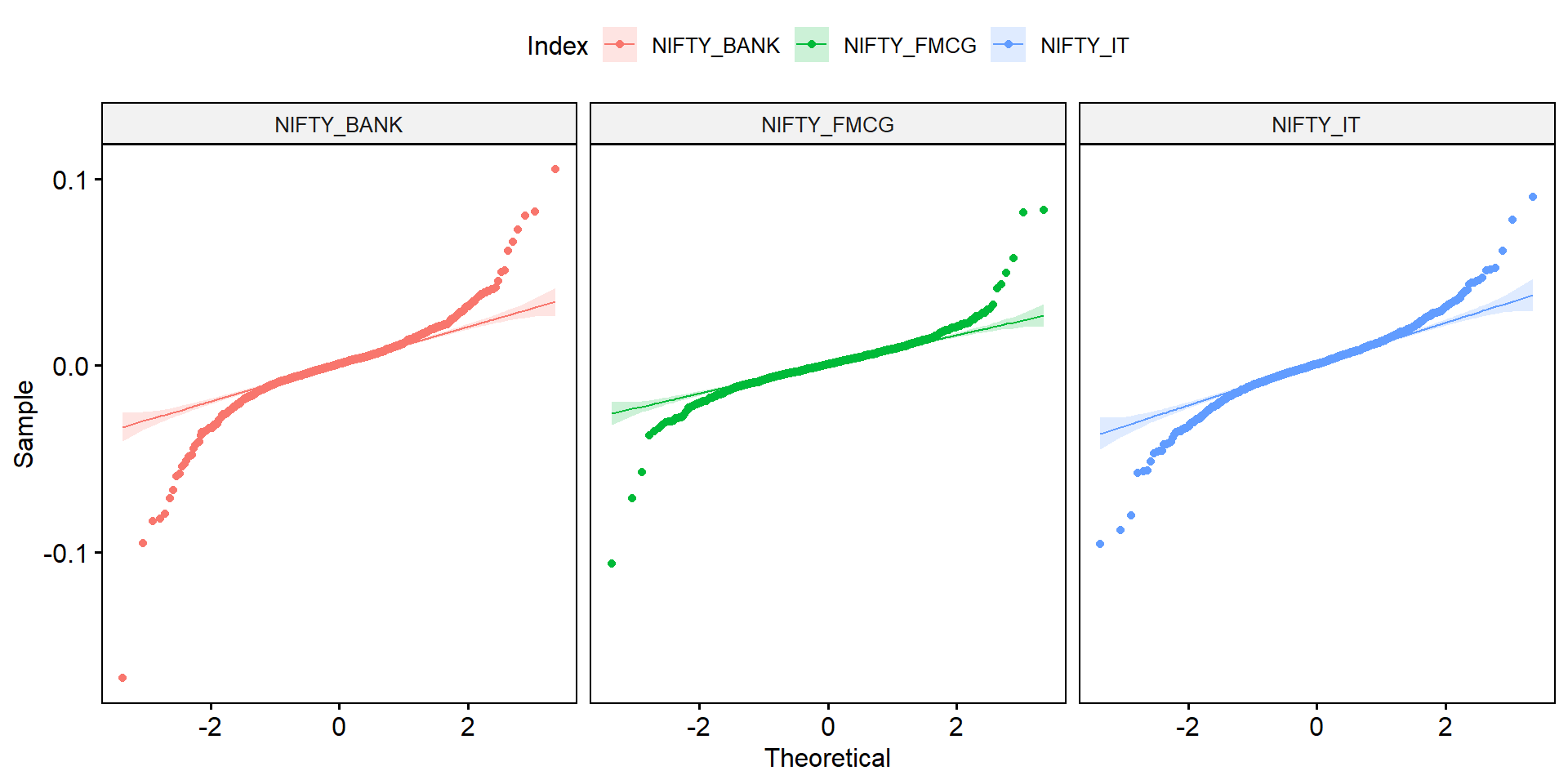
Interpretation: Returns show deviation from perfect normality, common in financial data.
7. Correlation Analysis
# Reshape returns to wide format
returns_wide <- sector_returns %>%
select(Date, Index, Return) %>%
pivot_wider(names_from = Index, values_from = Return)
# Correlation matrix
cor_matrix <- cor(returns_wide %>% select(-Date), use = "complete.obs")
# Correlation plot
corrplot(cor_matrix, method = "color", type = "upper",
addCoef.col = "black", tl.cex = 0.8, number.cex = 0.7,
title = "Correlation Between Sector Returns", mar = c(0,0,1,0))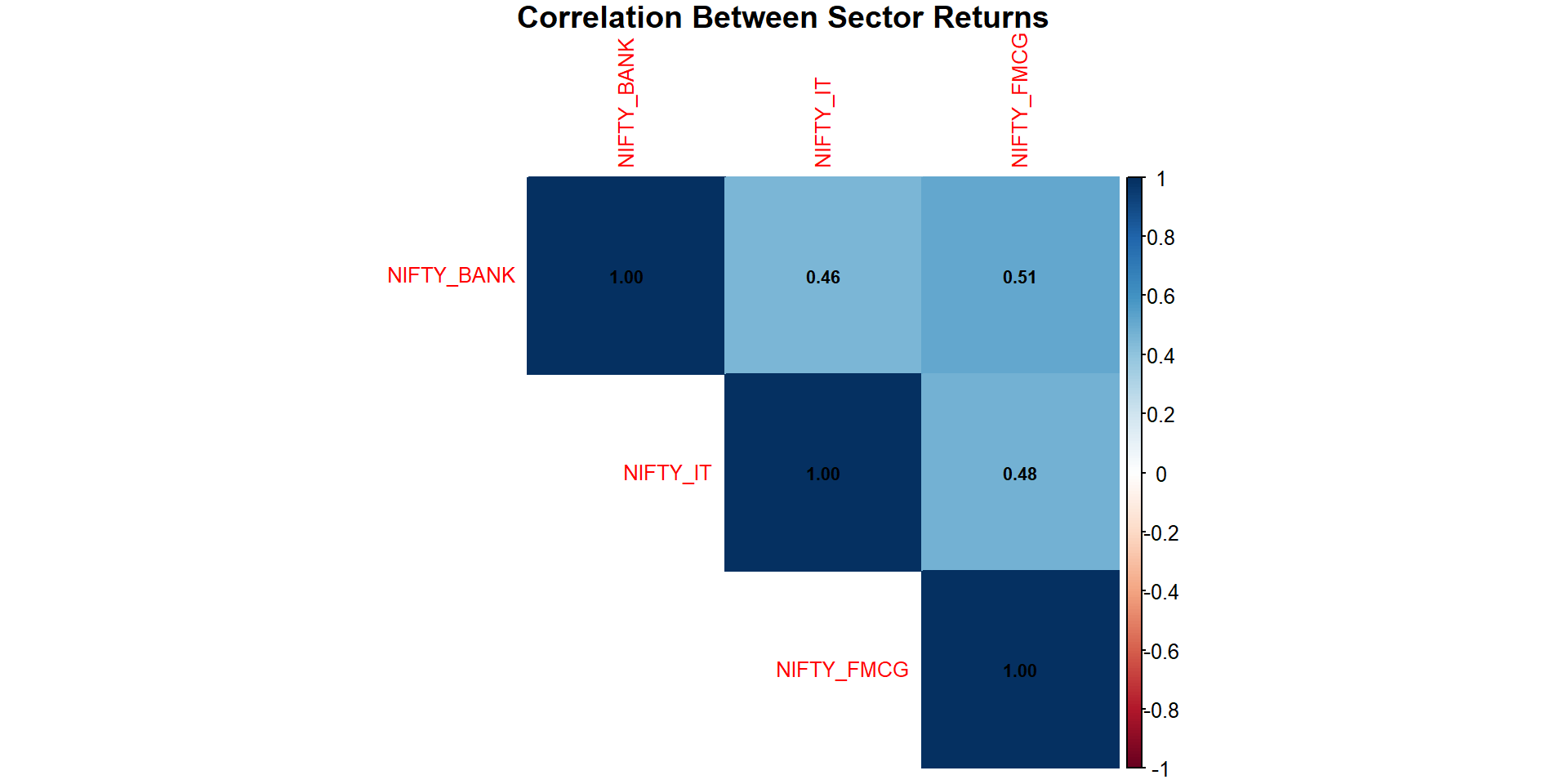
Interpretation: Positive correlations imply that sectors often move together. Banking and IT sectors show moderate correlation.